1StepFun · 2Imperial College London ·
3Peking University · 4Shanghai Jiao Tong University ·
5The University of New South Wales
*Corresponding author: tianfei@stepfun.com
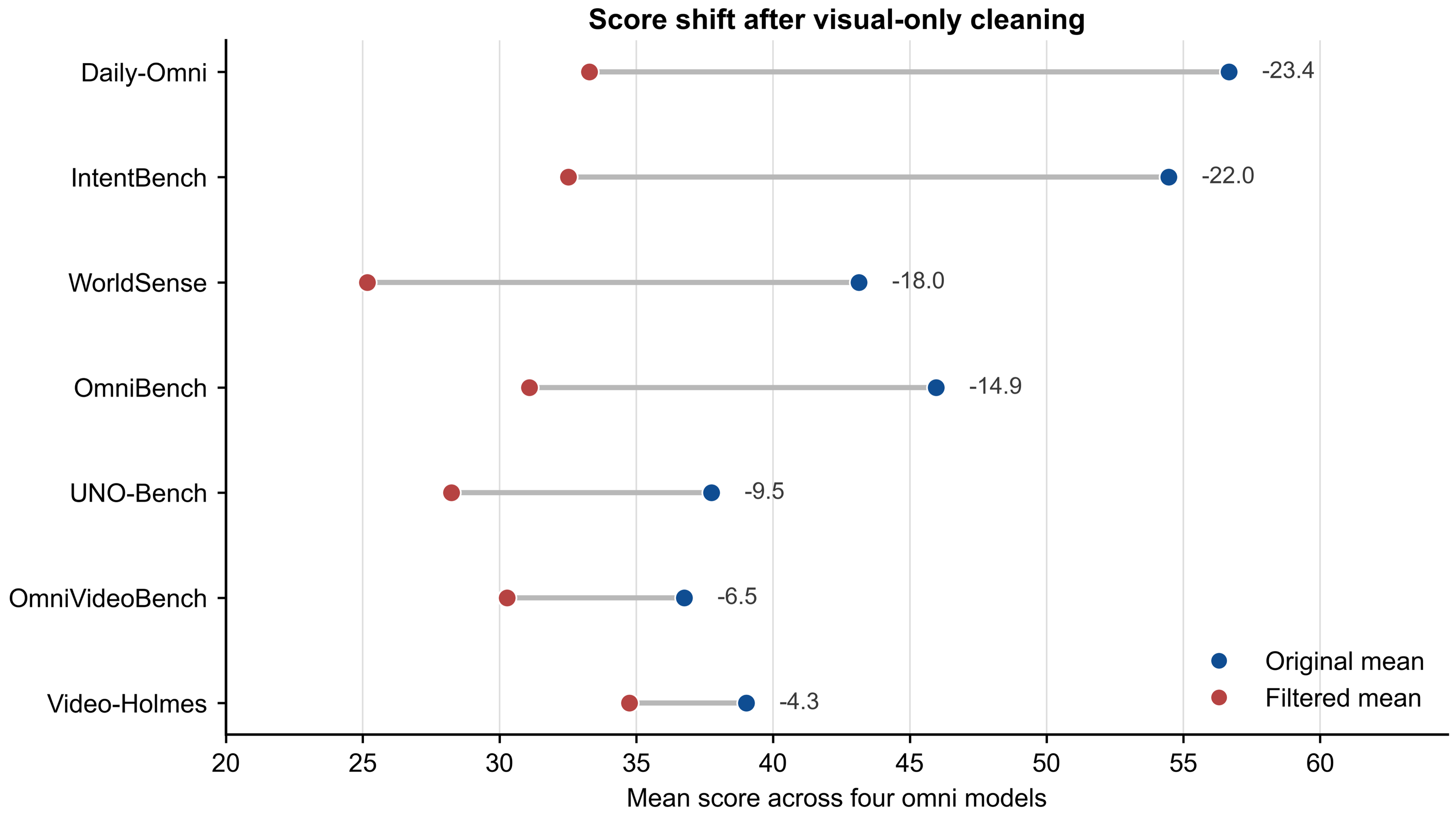
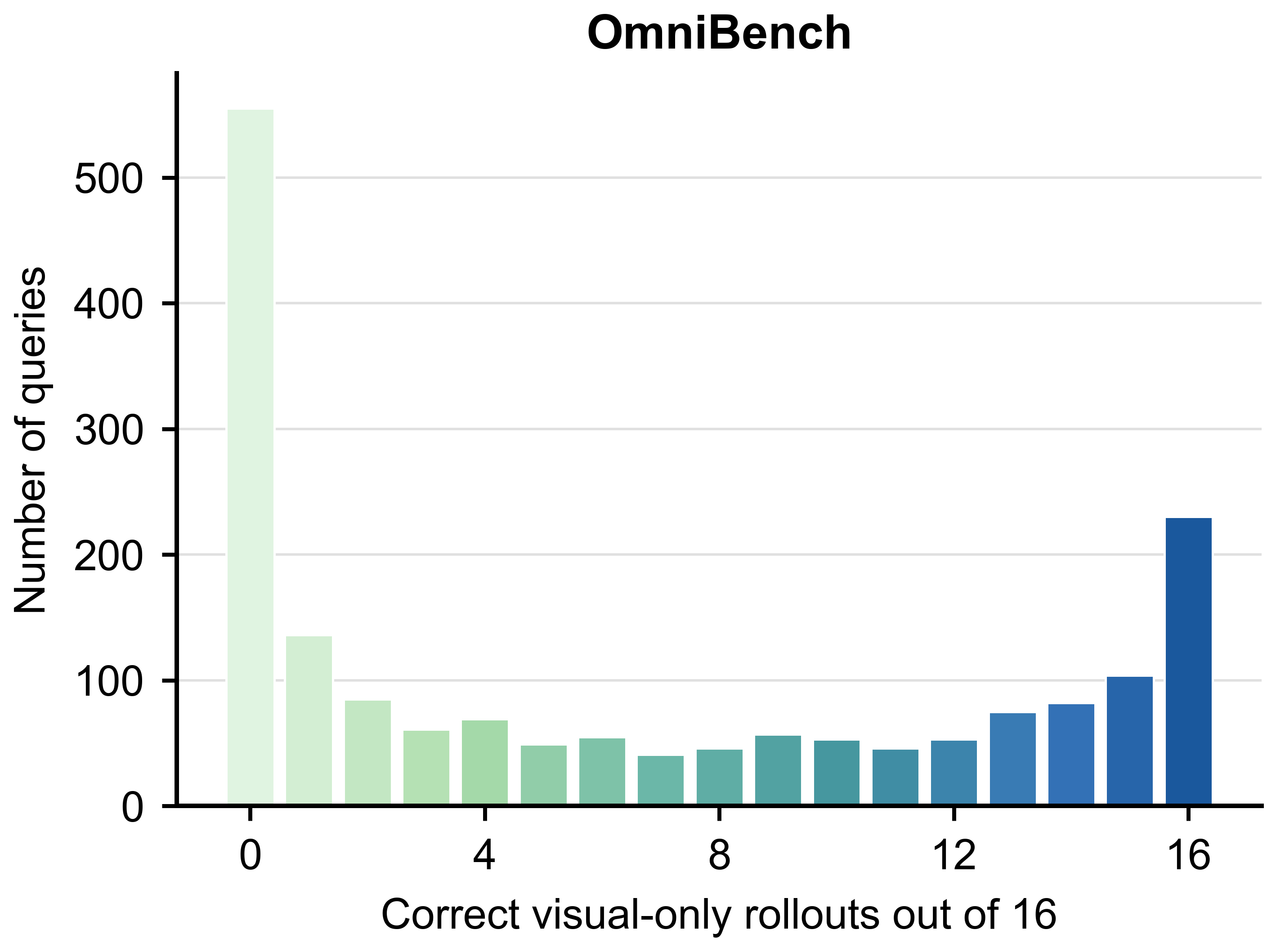
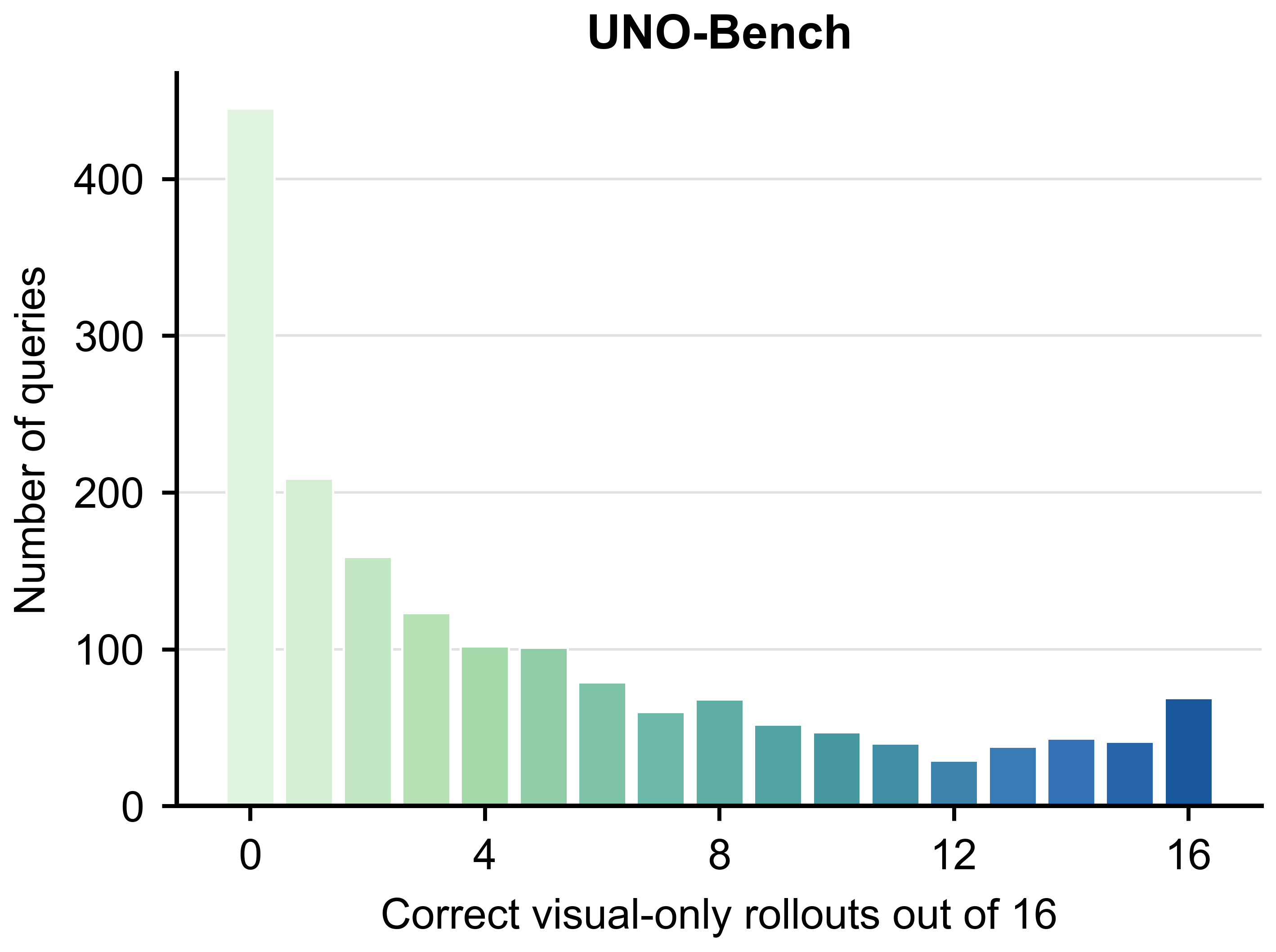
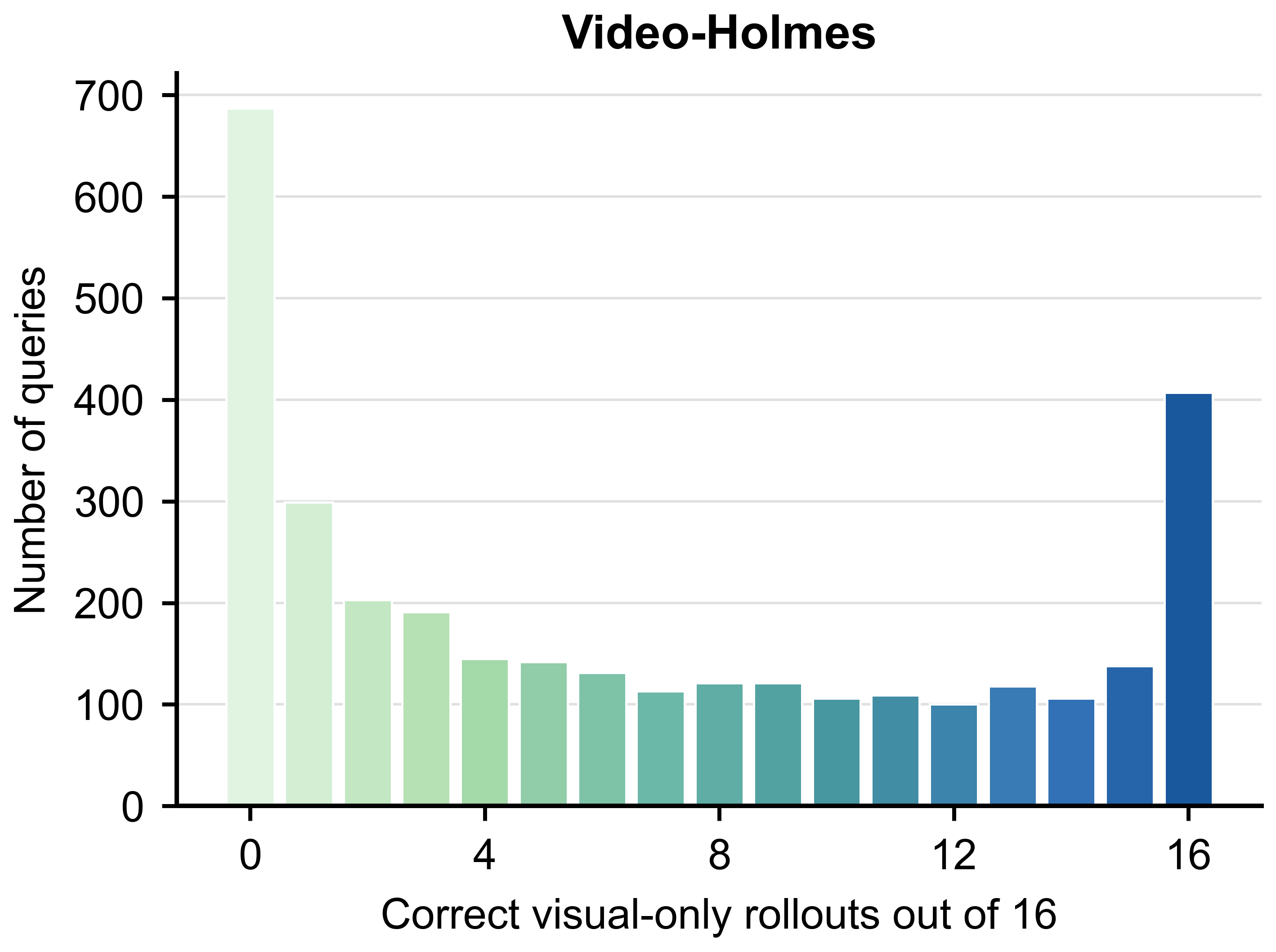
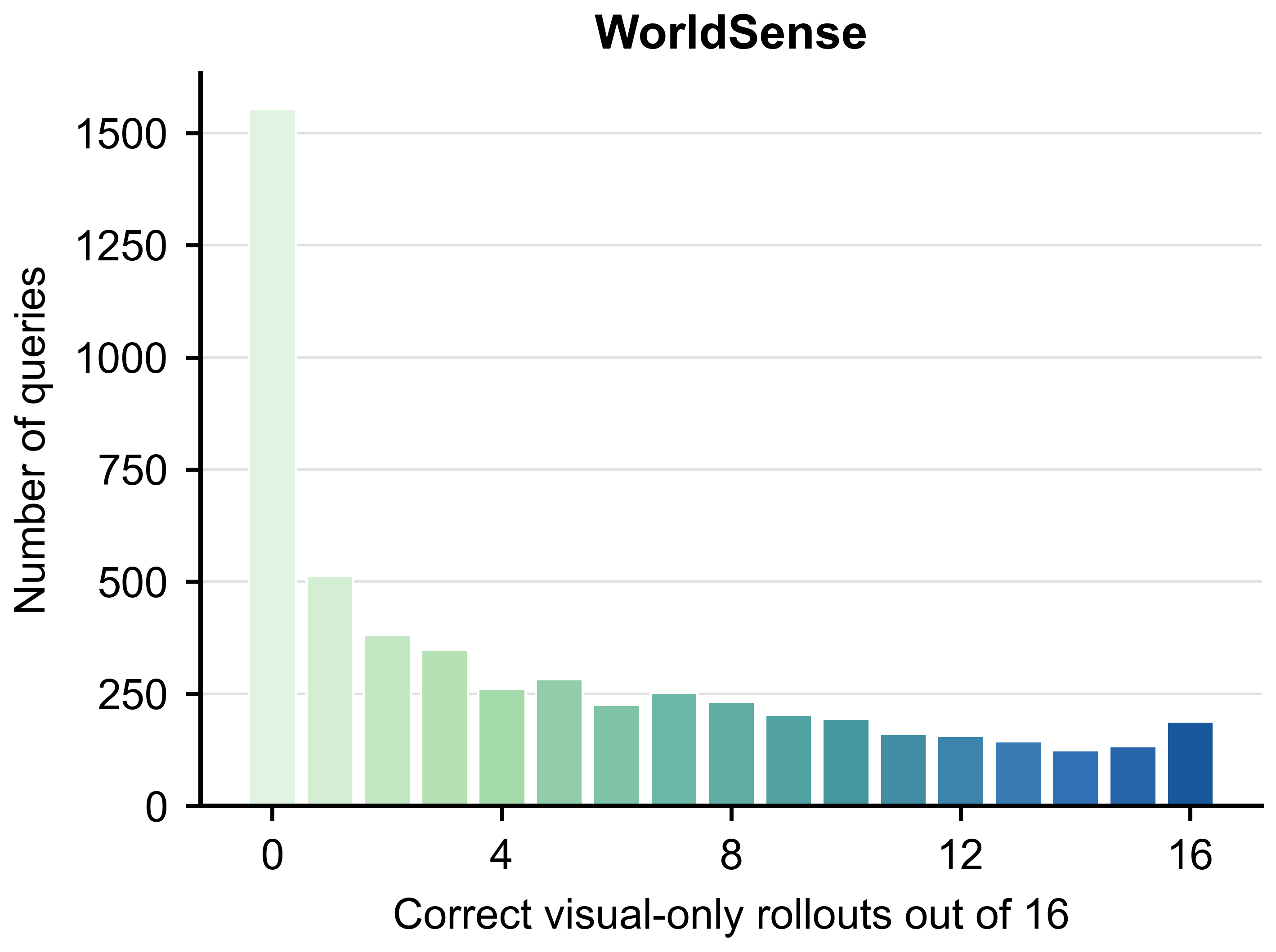
Fig. 1 exposes the central measurement issue: benchmark scores can drop substantially
after removing queries that are already answerable from visual input and the question.
Key findings
What should readers take away?
01
Visual shortcuts can inflate omni-modal scores.
Some audio-visual-language queries remain answerable from the visual stream and the
question alone. Fig. 1 shows why raw scores should not be read as direct evidence of
audio-visual-language integration.
02
Cleaning changes benchmark meaning, not just scores.
OmniClean audits 16,968 queries and keeps 8,551 under a fixed protocol. After
filtering, several benchmarks become less tied to visual or audio reference strength.
03
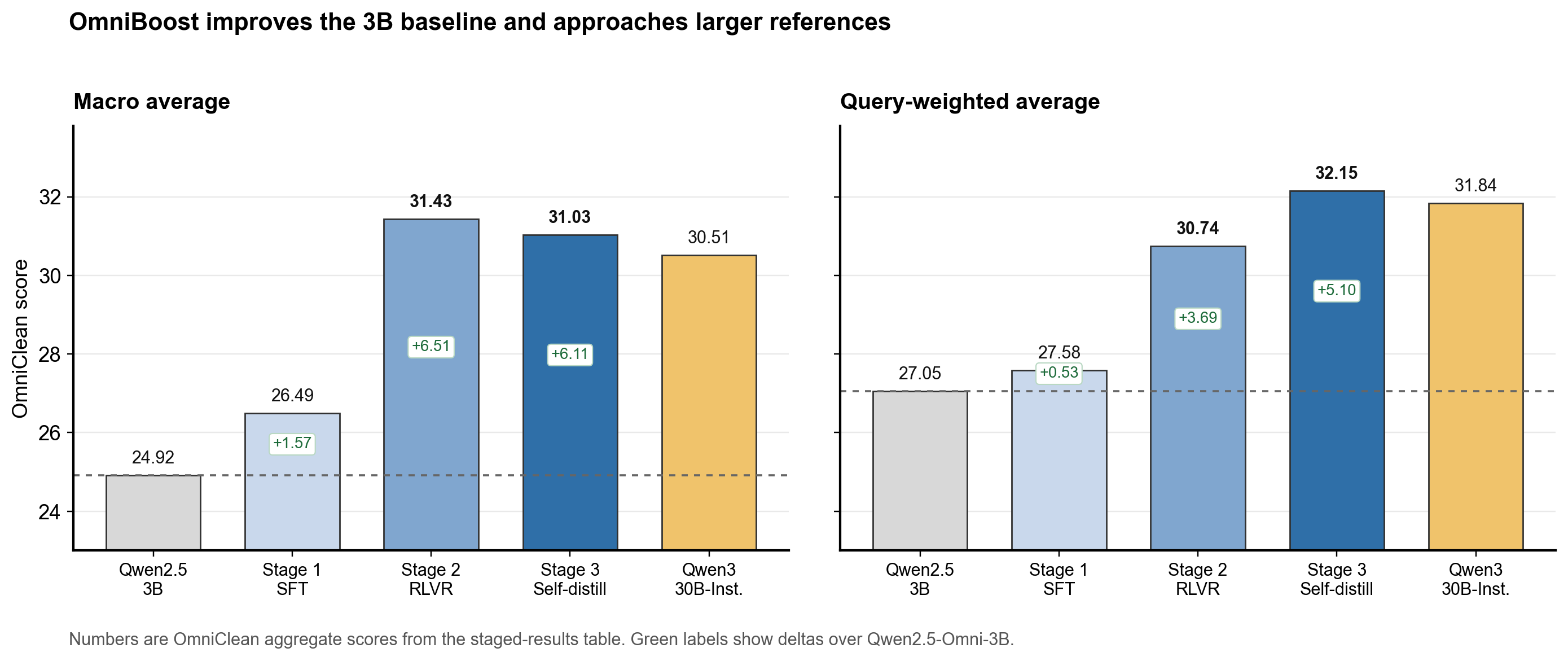
OmniBoost substantially improves the 3B baseline.
Stage 2 improves the macro average by +6.51 over Qwen2.5-Omni-3B. Stage 3 improves
the query-weighted average by +5.10 and slightly exceeds Qwen3-Omni-30B-Instruct.
04
Self-distillation helps, but the profile matters.
Synthetic audio-visual-text supervision improves the 3B lineage, yet Stage 2 and
Stage 3 emphasize different benchmark families and aggregation views.
Motivation
Visual shortcut is the first problem to control
Omni-modal language models are expected to integrate audio, visual inputs, and
language. However, a benchmark query may look audio-visual-language on paper while
still being recoverable from the visual input and the question alone.
This creates a measurement problem: model gains can come from stronger visual shortcut
exploitation rather than improved omni-modal reasoning. We therefore first construct a
cleaned evaluation view, then use it to study which training signals actually transfer.
OmniClean
A visually debiased evaluation view
OmniClean probes each evaluation query with image or video plus the original text
question while withholding audio. If a strong visual-language model recovers the
verifiable answer in this visual-only setting, the query is excluded from the cleaned
view. Benchmarks with protocol-specific exceptions are retained as full subsets.
9
audited omni benchmarks
16,968
queries before cleaning
8,551
retained OmniClean queries
Cleaning changes whether omni scores track vision or audio reference strength,
indicating that the cleaned view changes what the benchmark measures.
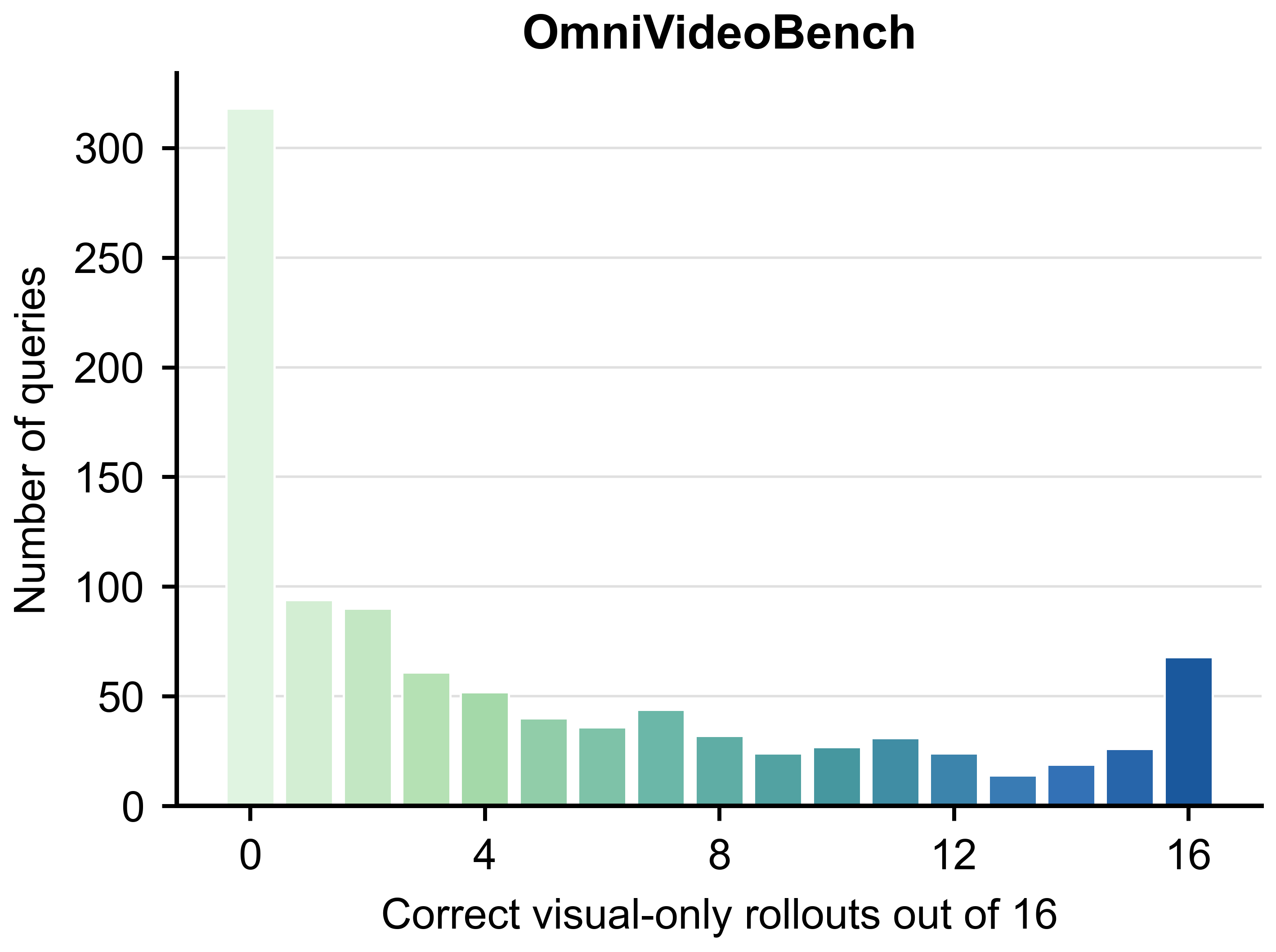
Leakage diagnostic
Visual-only solvability varies sharply by benchmark
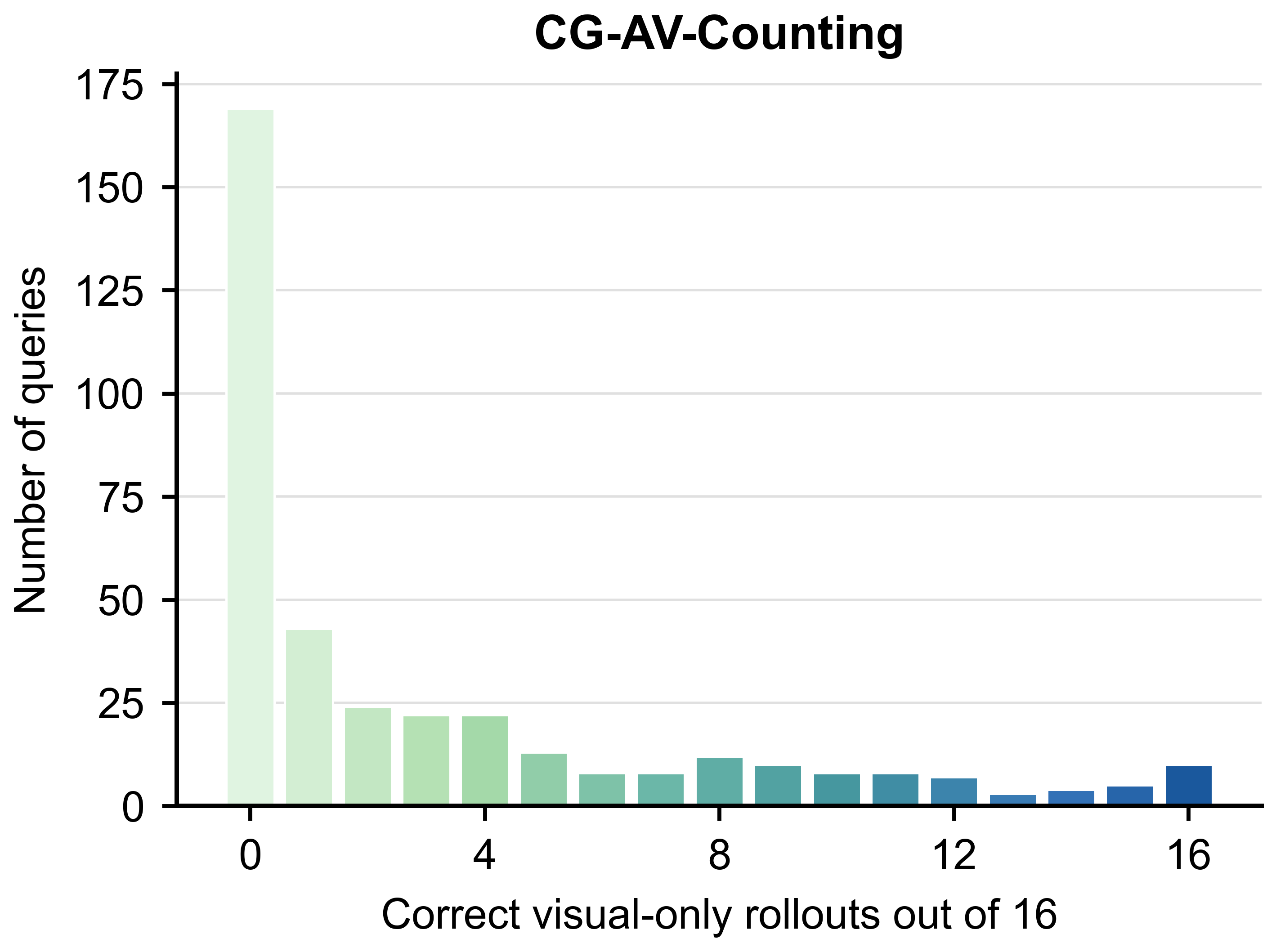
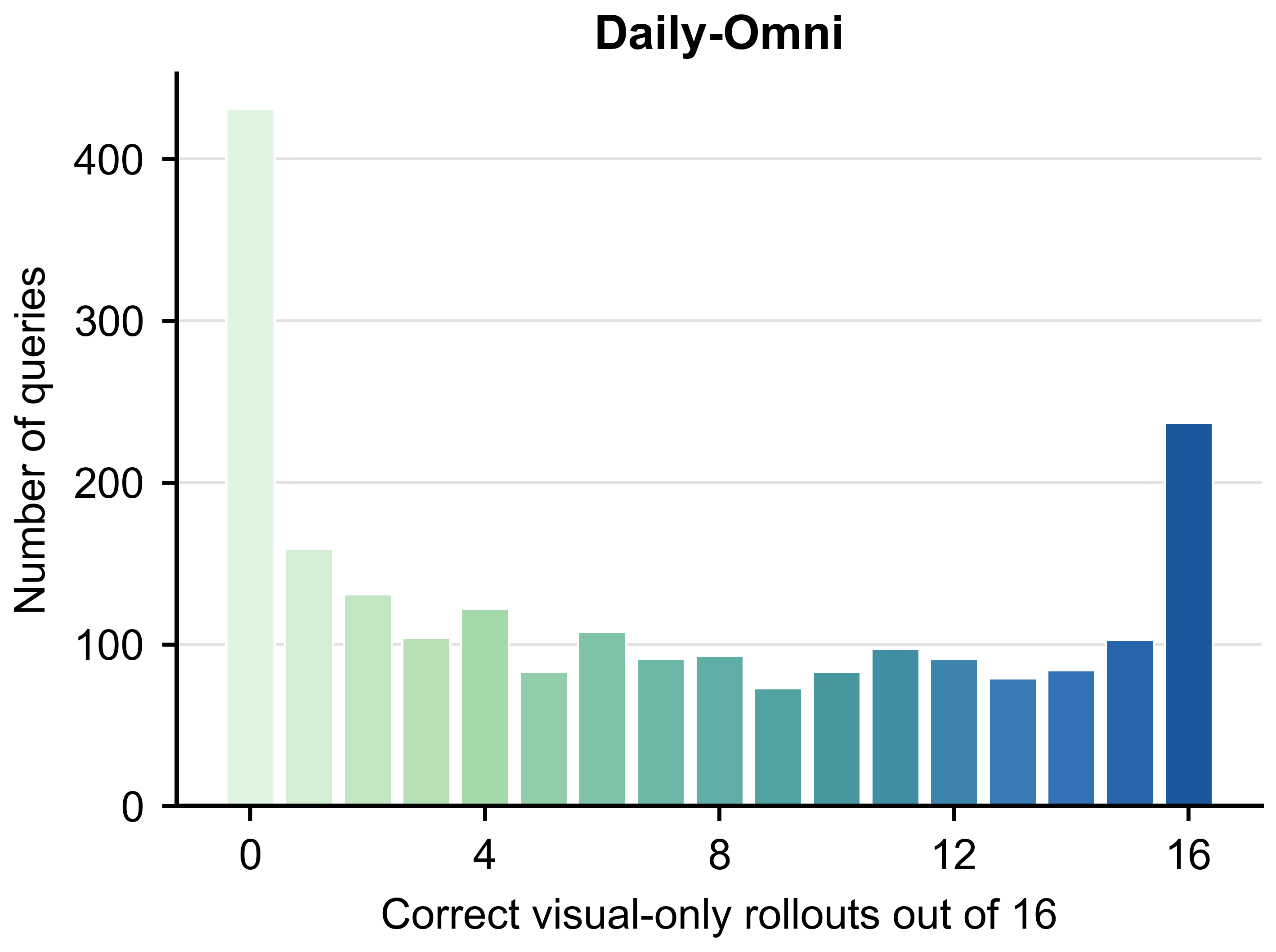
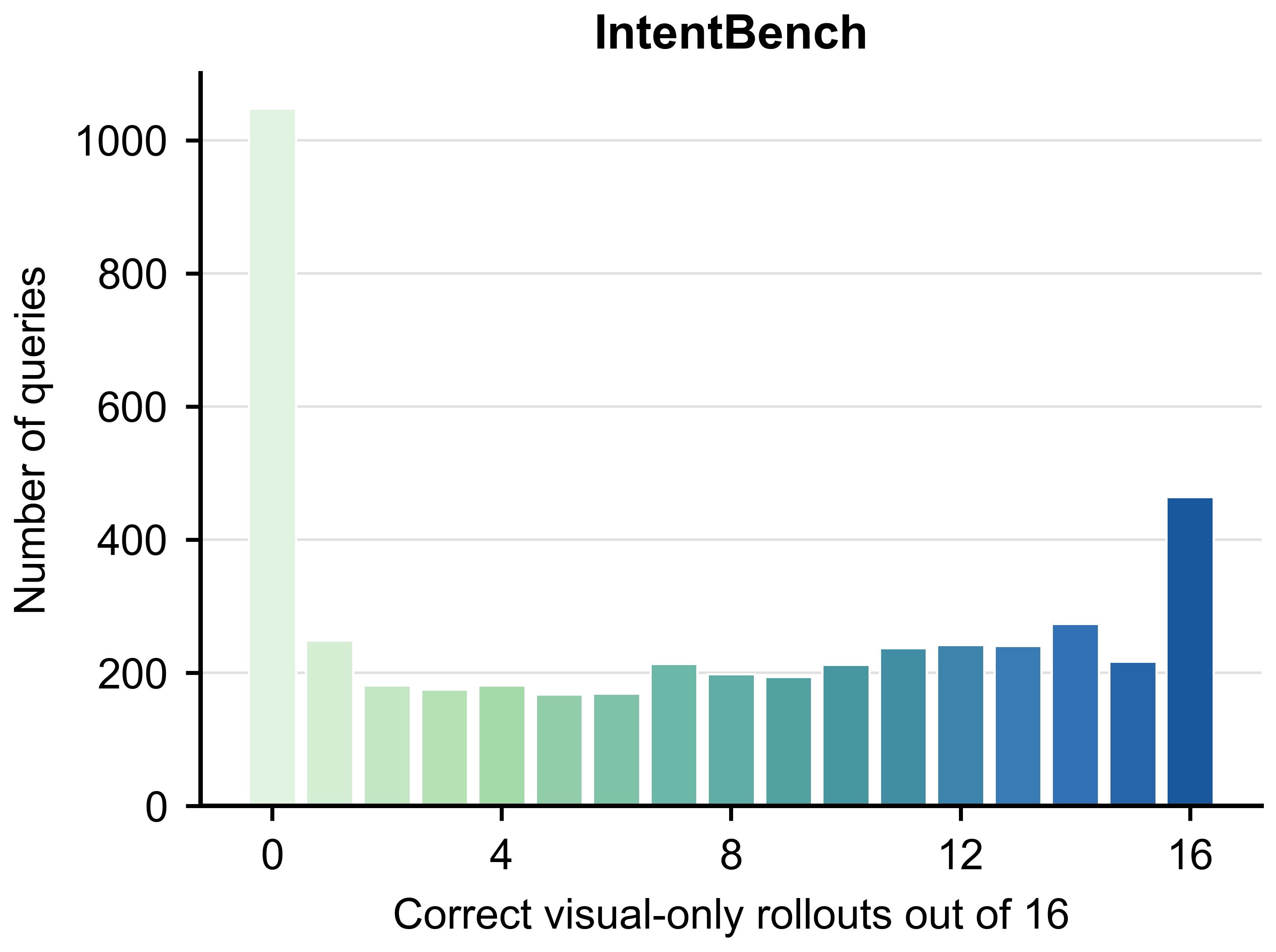
The diagnostic is query-level rather than benchmark-level: two benchmarks with similar
raw omni scores can contain very different amounts of visually answerable content.
OmniBoost
Testing what kind of post-training transfers to OmniClean
Stage 1
Mixed bi-modal SFT
Balanced audio-text, image-text, video-text, and text supervision.
Stage 2
Mixed-modality RLVR
Verifiable-reward optimization over text, visual, audio-image, and audio-video tasks.
Stage 3
Self-distillation SFT
SFT on filtered synthetic audio-visual-text traces generated by the same 3B lineage.
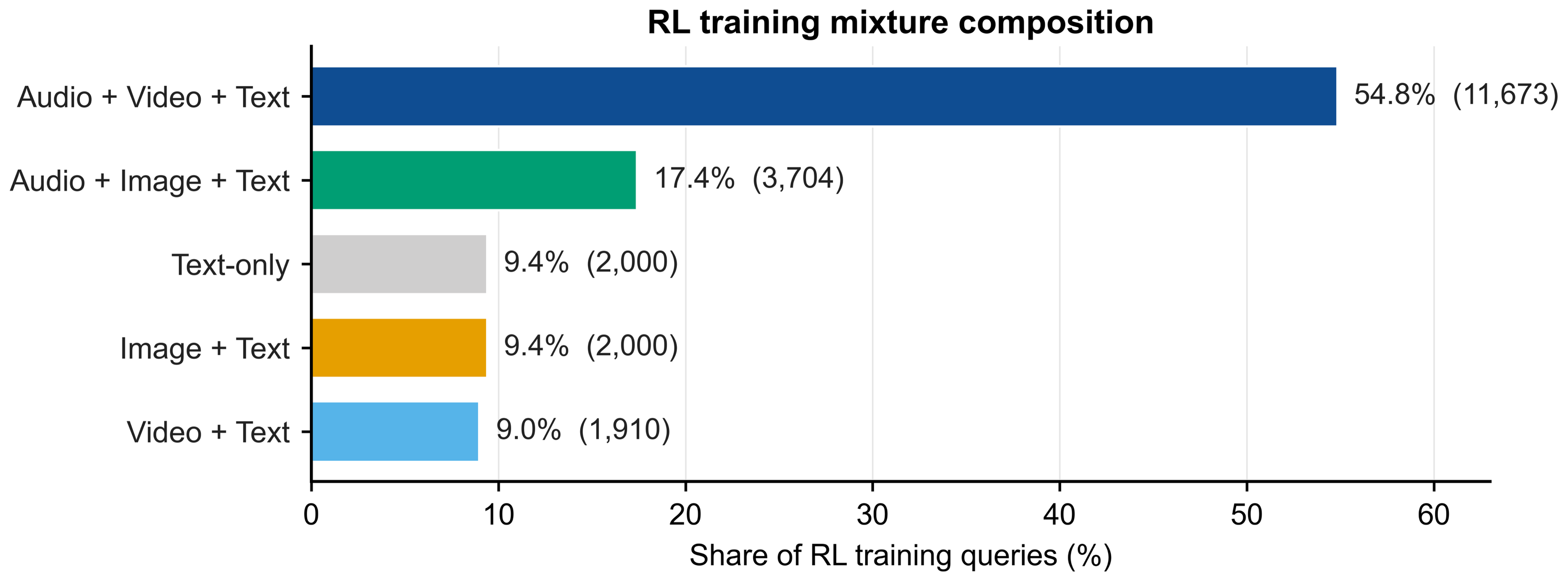
Stage 2 explicitly shifts optimization toward audio-video-text and audio-image-text
queries while retaining visual and textual replay.
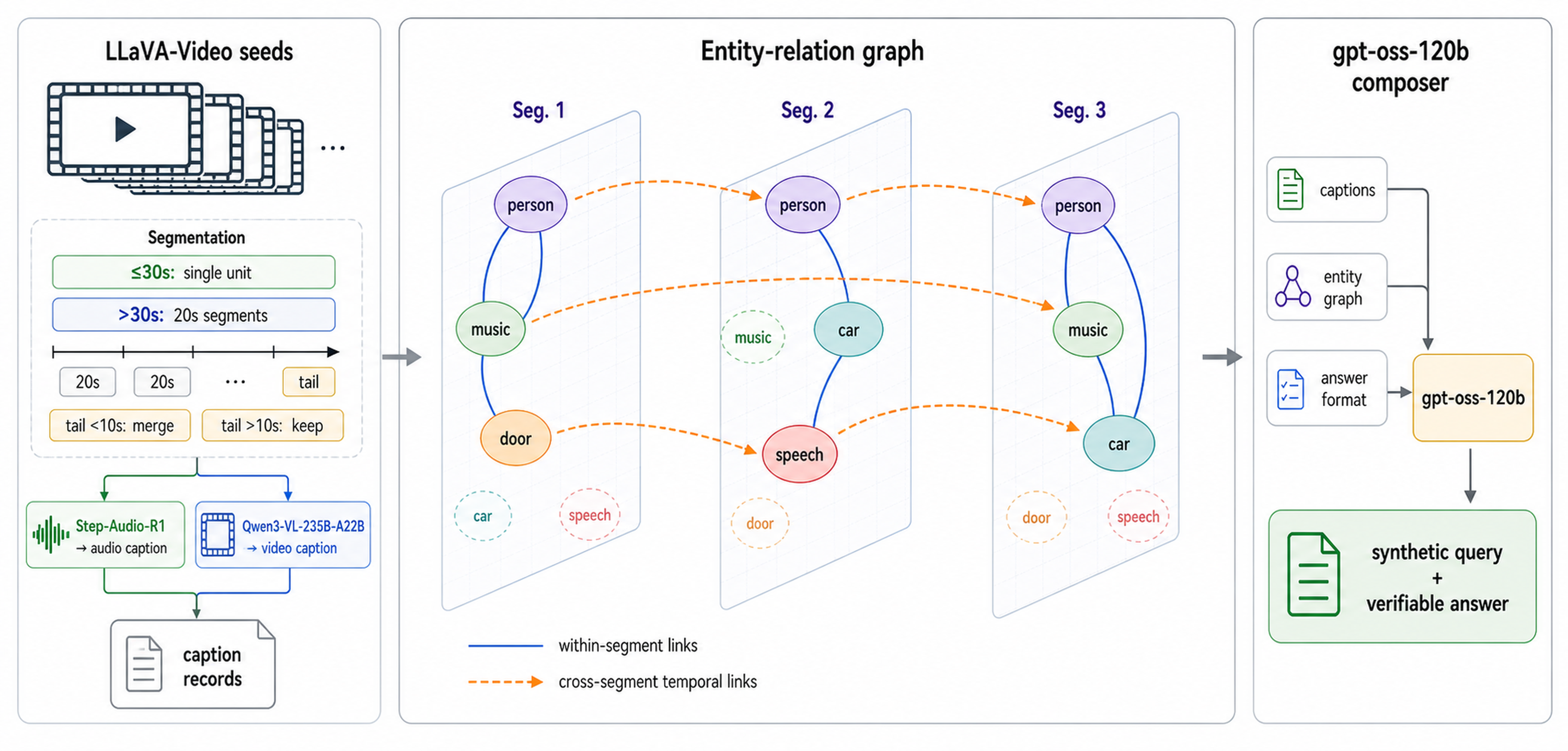
Stage 3 builds hard-matchable Synthetic Query pairs from dense audio/video captions
and entity-relation records before rollout filtering.
Results
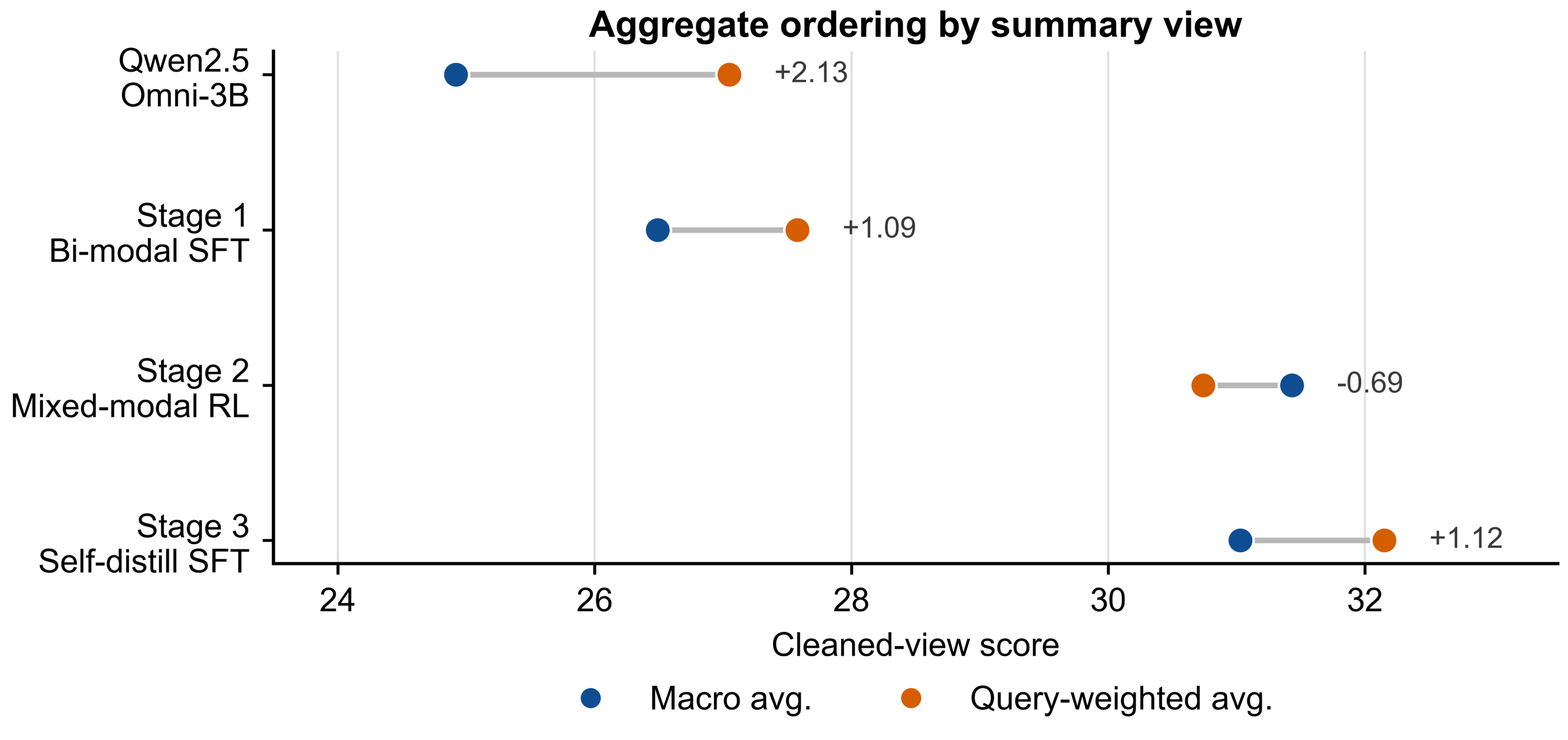
Stages improve the 3B baseline and approach larger references
Relative to Qwen2.5-Omni-3B, Stage 2 gives the strongest macro-average gain, while
Stage 3 gives the strongest query-weighted gain and slightly exceeds
Qwen3-Omni-30B-A3B-Instruct on that retained-query summary.
Stage 2 is strongest under benchmark-level macro averaging, while Stage 3 leads under
query-weighted averaging because larger retained subsets receive more weight.
Benchmark-level OmniBoost deltas relative to Qwen2.5-Omni-3B
Benchmark
Baseline
Stage 1
Stage 2
Stage 3
Daily-Omni
27.53
27.43 (-0.10)
38.05 (+10.52)
38.82 (+11.29)
IntentBench
29.57
30.15 (+0.58)
36.46 (+6.89)
37.03 (+7.46)
Video-Holmes
24.36
31.53 (+7.17)
47.07 (+22.71)
44.46 (+20.10)
WorldSense
24.91
24.11 (-0.80)
27.53 (+2.62)
24.71 (-0.20)
OmniBench
27.14
32.13 (+4.99)
43.24 (+16.10)
40.29 (+13.15)
UNO-Bench
21.41
23.68 (+2.27)
21.97 (+0.56)
23.35 (+1.94)
CG-AV-Counting
12.73
16.22 (+3.49)
19.65 (+6.92)
16.49 (+3.76)
OmniVideoBench
27.67
25.16 (-2.51)
21.00 (-6.67)
22.33 (-5.34)
AV-Odyssey
29.00
28.00 (-1.00)
27.87 (-1.13)
31.80 (+2.80)
Macro Avg.
24.92
26.49 (+1.57)
31.43 (+6.51)
31.03 (+6.11)
Query-Weighted Avg.
27.05
27.58 (+0.53)
30.74 (+3.69)
32.15 (+5.10)
Synthetic query construction
Synthetic data and filtering turn caption evidence into verifiable supervision
Construct
Caption and entity records
Audio and video captions are organized into within-segment and temporal relation scaffolds.
Generate
Hard-matchable queries
Synthetic audio-visual-text questions are constrained to verifiable answer formats.
Filter
F1-F3 quality passes
Rollouts are filtered by difficulty, perception defects, malformed outputs, and answer consistency.
Caption records, entity relations, answer-format constraints, and rollout filtering are
used to construct verifiable supervision for the same 3B model lineage.
@misc{liu2026omnicleanomniboost,
title = {Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation},
author = {Liu, Che and Ma, Lichao and Zhang, Xiangyu Tony and Zhang, Yuxin and Zhang, Haoyang and Yang, Xuerui and Tian, Fei},
year = {2026},
note = {Preprint}
}